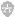深度学习已进入瓶颈期,模拟人类神经结构将是突破口?
2017-10-05 23:39:11 来源:37度医学网 作者: 评论:0 点击:
实际上,你听说过的几乎每一个关于人工智能的进步,都是由 30 年前的一篇阐述多层神经网络的训练方法的论文演变而来,它为人工智能在最近十年的发展奠定了基础,但要保持这种进步,就要面对人工智能严重的局限性。

图丨1986年辛顿与他人合作的神经网络论文
如今,我正站在多伦多市中心一栋高级大厦七层的一个大房间里,这里即将成为世界中心。这里就是新成立的人工智能研究所Vector Institute的所在地。研究所的联合创始人乔丹·雅各布(Jordan Jacobs)带着我来到这里。该研究所于今年秋天正式成立,致力于成为全球人工智能中心。

图丨杰弗里·辛顿(Geoffrey Hinton)
我们为了拜访杰弗里·辛顿(Geoffrey Hinton)来到多伦多。他是“深度学习”之父,正是这个技术让人工智能发展到今天这般炙手可热。雅各布说:“我们30年后再往回看,杰弗里就是人工智能(我们认为深度学习就是人工智能)的爱因斯坦。”
在人工智能领域最顶尖的研究人员当中,辛顿的引用率最高,超过了排在他后面三位研究人员的总和。他的学生和博士后领导着苹果、Facebook和OpenAI的人工智能实验室;辛顿本人是谷歌大脑(Google Brain)人工智能团队的首席科学家。
事实上,人工智能在最近十年里取得的几乎每一个成就,包括语音识别、图像识别,以及博弈,在某种程度上都能追溯到辛顿的工作。

Vector Institute研究中心进一步升华了辛顿的研究。在这里,谷歌、Uber、Nvidia等美国和加拿大的公司正努力将人工智能的技术商业化。资金到位的速度比雅各布想象的更快;他的两个联合创始人调研了多伦多的公司,发现他们对人工智能专家的需求是加拿大每年培养的人数的10倍。
某种意义上,Vector研究所是全球深度学习运动的原爆点:(无数公司)靠这项技术牟利,训练它、改进它、应用它。到处都在建造数据中心,创业公司挤满了摩天大楼,整整新一代学生也纷纷投身这一领域。

图丨Vector Institute成员
当你站在空旷得能听得到回声、但又即将被占满的Vector研究所时,会感觉自己置身于一个未知世界的起点。但是,深度学习最核心的理念早已出现。1986年,辛顿联合同事大卫·鲁姆哈特(David Rumelhart)和罗纳德·威廉姆斯(Ronald Williams),发表了一篇突破性的论文,详细介绍了一种叫作“反向传播”(backpropagation,简称backprop)的技术。普林斯顿计算心理学家乔恩·科恩(Jon Cohen)将反向传播定义为“所有深度学习技术的基础。”
归根结底,今天的人工智能就是深度学习,而深度学习就是反向传播。我们很难相信反向传播已经出现了30多年。为什么它会在沉寂多年后突然爆发?其实,当你理解了反向传播的发展历史,也就会开始明白人工智能的现状,并且意识到,我们也许并非处于一场变革的起点,而是终点。
深度学习,一份迟到26年的礼物
辛顿现在是多伦多大学的荣誉教授,大部分时间在谷歌工作。从 Vector Institute 走到辛顿办公室的路程就是这座城市的一种活广告。特别是在夏天的时候,你会明白为什么来自英国的辛顿在 1980 年代离开匹兹堡的卡耐基梅隆大学并移居此地。
当你来到室外的时候,会感觉自己仿佛真的进入了大自然,甚至在金融区附近的市中心也是如此。我认为这是因为城市里的空气很湿润。多伦多坐落在森林峡谷上,被誉为“花园城市”。在多伦多完成城市化后,,当地政府为树冠密度设立了严格的规定。从飞机上俯瞰多伦多,整座城市被笼罩在一片苍翠之中。

图丨多伦多鸟瞰
多伦多是北美第四大城市(仅次于墨西哥、纽约和洛杉矶),也是其中最多元化的城市:一半以上的居民出生于加拿大以外的地方。你在城市里走一圈就能发现,这里的科技圈更国际化,不像旧金山都是穿着连帽衫的白人青年。这里有免费医疗和优质的公立学校,居民都很友好,政治秩序偏左而稳定——这些因素吸引了像辛顿这样的人。辛顿表示,他是因为“伊朗门”事件而离开美国的,我在午餐前见到他时就谈到此事。
“卡耐基梅隆大学的很多人认为,美国有充分的理由侵略尼加拉瓜,”他说,“他们或多或少认为尼加拉瓜属于美国。”辛顿告诉我,他最近在一个项目上取得了重大突破:“我找到了一位非常优秀的初级工程师一起合作。”他指的是莎拉·萨伯尔(Sara Sabour)女士。萨伯尔是伊朗人,在美国申请工作签证时遭到拒签。后来,谷歌的多伦多办公室帮她解决了签证问题。
69 岁的辛顿长着一副像圆梦巨人(译注:圆梦巨人是英国儿童文学作家罗尔德·达尔的同名小说的主人公,性格善良)那样友善、瘦削的英式面孔、薄嘴唇、大耳朵、高鼻梁。他出生于英格兰的温布尔顿。他说话时就像在念一本少儿科普读物一样:好奇、投入、解说时充满激情。他很有趣,也很健谈。我们谈话时,他全程站立,因为坐着太痛苦了。

图丨杰弗里·辛顿(Geoffrey Hinton)
辛顿告诉我:“我在 2005 年 6 月坐下了,我错了。”这句话让我感到费解,于是他解释道,他的背部椎间盘有问题。这意味着,他不能坐飞机。当天早些时候,他不得不把一个类似冲浪板的奇怪装置带到牙医办公室。医生在为他检查一个隐裂牙根时,他就躺在那块板子上。
在 1980 年代,辛顿就已经是一位神经网络专家了。神经网络是人脑神经元和突触网络的一个简化模型。然而,当时科学界认为,把人工智能领域导向神经网络方向是自寻死路。
最早的神经网络Perceptron诞生于1960年代,被誉为迈向类人机器智能的第一步。1969年,麻省理工学院的马文·明斯基(Marvin Minsky)和西摩·帕尔特(Seymour Papert)发表了著作《Perceptrons》,用数学的方法证明这种网络只能实现最基本的功能。这种网络只有两层神经元,一个输入层和一个输出层。如果在输入层和输出层之间加上更多的网络,理论上可以解决大量不同的问题,但是没人知道如何训练它们,所以这些神经网络在应用领域毫无作用。除了少数像辛顿这样不服输的人,大多数人看过这本书后都完全放弃了神经网络的研究。

图丨马文·明斯基(Marvin Minsky)
辛顿在 1986 年取得了突破,他发现反向传播可以用来训练深度神经网络,即多于两层或三层的神经网络。但自那以后又过了 26 年,不断增强的计算能力才使这一理论得以证实。辛顿和他在多伦多的学生于 2012 年发表的一篇论文表明,用反向传播训练的深度神经网络在图像识别领域打败了当时最先进的系统——“深度学习”终于面世。
在外界看来,人工智能似乎一夜之间突然爆发了,但对辛顿而言,这只是一个迟到的礼物。
矢量无所不能,反向传播已被榨干潜力?
神经网络通常被比喻成一块有很多层的三明治。每层都有人工神经元,也就是微小的计算单元。这些神经元在兴奋时会把信号传递给相连的另一个神经元(和真正的神经元传导兴奋的方式一样)。每个神经元的兴奋程度用一个数字代表,例如0.13或32.39。两个神经元的连接处也有一个重要的数字,代表多少兴奋从一个神经元传导至另一个神经元。这个数字是用来模拟人脑神经元之间的连接强度。数值越大,连接越强,从一个神经元传导至另一个神经元的兴奋度就越高。
实际上,图像识别是深度神经网络最成功的应用之一。正如 HBO 的电视剧《硅谷》中就有这样一个场景:创业团队开发了一款程序,能够辨认图片中有没有热狗。现实生活中确实有类似的程序,但这在 10 年前是无法想象的。要让它们发挥作用,首先需要一张图片。举一个简单的例子,让神经网络读取一张宽 100 像素、高 100 像素的黑白照片,输入层每一个模拟神经元的兴奋值就是每一个像素的明亮度。那么,在这块三明治的底层,一万个神经元(100x100)代表图片中每个像素的明亮度。
以上图解来自辛顿、大卫·鲁姆哈特(David Rumelhart)和罗纳德·威廉姆斯(Ronald Williams)有关“误差传播”的开创性著作。
然后,将这一层神经元与另一层神经元相连,假如一层上有几千个神经元,它们与另一层上的几千个神经元相连,然后一层一层以此类推。最后,这块三明治的最顶层,即输出层,只有两个神经元,一个代表“热狗”,另一个代表“不是热狗”。这个过程是为了训练神经网络在图片中有热狗时将兴奋仅传导至第一个神经元,而在图片中没有热狗时将兴奋仅传导至第二个神经元。这种训练方法就是辛顿开发的反向传播技术。
反向传播的原理极其简单,但它需要大量的数据才能达到最佳效果。正因如此,大数据对人工智能至关重要。也正式出于这个原因,Facebook 和谷歌对大数据求之若渴,Vector Institute 决定在加拿大最大的四家医院附近设立总部,并与他们开展数据合作。
在上面的例子里,所需的数据是几百万张图片,部分图片中有热狗,其他图片中没有。重要的是,图片要被标记出是否带有热狗。当你刚刚创建自己的神经网络时,神经元之间连接的强度是随机的。换句话说,每个连接传导的兴奋值也是随机的,就像人脑中的突触还没有完全成形。反向传播的目标是通过改变这些数值让神经网络发挥作用:当你将一张热狗图片传导至底层时,顶层的“热狗”就能产生兴奋。

假设你用来训练神经网络的第一张图片是钢琴照片。你将这张 100x100 的图片的像素强度转换为一万个数字,每个数字代表神经网络底层的单个神经元。兴奋根据相邻层神经元之间的连接强度在网络中传播,最终到达最后一层,上面仅有两个神经元,分别代表图片中是否有热狗。
由于那张图片上是一架钢琴,理想条件下,“热狗”神经元上的数字应该是 0,而“不是热狗”神经元上应该是一个大于 0 的数字。但如果事实并非如此呢?如果神经网络的判断是错的呢?反向传播是对神经网络中每一个连接强度的重置过程,从而修正网络在特定训练数据中的错误。
反向传播是如何修正神经网络的错误的?第一步是分析最后两个神经元的错误程度:预设兴奋值和应有兴奋值之间相差多少?第二步是分析导向倒数第二层神经元中每个连接对该误差的作用。重复这些步骤,直至网络最底层的神经元连接。此时,你会知道每个连接对误差的作用大小。最后,通过改变每一个数字,将整体误差降至最低。这一方法被称为“反向传播”,因为误差是从网络的输出层逆向(或向下)传播的。
神奇的是,用数百万或数十亿张图片来进行训练时,神经网络会逐渐提升其识别热狗的准确度。更厉害的是,这些图像识别网络的每一层都逐渐学会用类似人类视觉系统的方式“看”图片。例如,第一层会探测“边”,这层中的神经元看到“边”的时候会产生兴奋作用,而在其他地方不会;它上面的第二层神经元能探测到边的组合,比如角;第三层能识别形状;第四层能找到分辨类似于“切开的面包(可以用于热狗)”或“没切开的面包(一般不用于热狗)”这样的东西,因为上面的神经元可以对任意一种情况发生反应。换言之,神经网络在未经编程的情况下能自行演变为上下多层结构。

人们对神经网络惊奇不已,不仅仅是因为它们善于对热狗或其他事物的图片进行归类,而是因为它们似乎能建立思维模型。这一点在理解文字的时候能看得更清楚。例如,让一个简单的神经网络读取维基百科上数十亿字的文章,并训练它针对每一个词输出一长串的数字,每一个数字代表某层中每个神经元的兴奋度。如果将每个数字看作一个复杂空间中的坐标,神经网络就为每个单词找到了空间坐标中的一个点(在这里也就是一个向量)。
接下来,让神经网络对维基百科页面上位置相邻的词给出相似的坐标,不可思议的事情出现了:在这个复杂的空间中,含义相近的词的位置开始集中。也就是说,“疯狂”和“神经错乱”的坐标相近,“三”和“七”的坐标相近,诸如此类。而且,所谓的矢量算法能用“巴黎”的矢量减去“法国”的矢量,加上“意大利”的矢量,最后得出的坐标靠近“罗马”。这些操作的前提是,没有任何人明确告知神经网络,罗马之于意大利等同巴黎之于法国。
辛顿说,“真是太神奇,太让人震惊了。”神经网络似乎能抓取图像、文字、某人说话的录音、医疗数据等事物,将它们放到数学家所说的高维矢量空间里,使这些事物之间的距离远近反映真实世界的一些重要特点。辛顿相信,这就是大脑的运作方式。
他在解释什么是想法的时候举了一个例子。“我能用一串文字来解释我在想什么,比如“约翰在想,哎呀’”。但是,这个想法意味着什么?我们脑袋里并非存在一个前引号,一个‘哎呀’和一个后引号,或者它们组成的一个整体。脑袋里出现的其实是一种神经活动模式。”如果你是一位数学家,你的神经活动模式在矢量空间里表现为,每个神经元的活动对应为一个数字,每个数字对应为一个相当大的矢量坐标。辛顿认为,这就是人的想法:不同的向量在跳舞。
多伦多最顶级的人工智能研究所的名字就取自这个理念。Vector Institute(向量研究所)这个名字就是辛顿取的。

辛顿创造了某种现实扭曲场,一种充满笃定和热忱的气氛,让你感觉向量无所不能。毕竟,他们发明了自动驾驶汽车、检测癌症的计算机,还有同声传译机器。现在,这位富有魅力的英国科学家又在谈论高维空间的梯度下降。
不过,当你冷静一下以后会想起来,这些“深度学习”系统还很蠢,虽然它们偶尔表现得很聪明。计算机看到桌子上的一堆甜甜圈时,自动给它加上标注:桌子上的一堆甜甜圈。看起来,计算机有一定的理解能力。但是,同一个程序看到一个正在刷牙的女孩的照片时,得出的结论可能是“这个男孩拿着一个棒球棒”。由此可看出,这种理解能力,即便存在,其实也非常浅薄。
神经网络只是不具备思维能力的模式识别机。鉴于它们的实用性,人们纷纷将其融入各种软件。即便在最佳条件下,它们只表现出有限的智能,很容易被糊弄。一个会识别图像的深度神经网络在你修改一个像素或加上一个人类察觉不到的视觉干扰后,就完全失灵了。自动驾驶汽车无法应对陌生情境。机器无法解析需要生活常识的语句。
深度学习能用某种方式模仿人脑行为,但只能停留在一个浅薄的层面。正因如此,它有时表现出较低的智能水平。确实,反向传播不是在深度研究大脑、剖析思想构成的过程中发现的。机器像动物一样,在反复试验的过程中学习。它在发展过程中的大多数跃进并未涉及神经科学的新理念;这些进展是数学和工程学多年的技术进步。我们所知道的智能,在无限的未知面前根本不值一提。

多伦多大学的助理教授戴维·杜文多(David Duvenaud)和辛顿在同一个部门。他认为,深度学习就像物理学出现之前的工程学。“有人写了一篇论文,说‘我建了座桥,它立起来了!’另一个人写了篇论文:‘我建了座桥,它倒下了,但我后来加了几个柱子,它就能撑住了。’于是,柱子火了。有人提出建拱桥,于是人们都说‘拱桥太棒了!’杜文多继续说:“有了物理学以后,你才能明白什么行得通,以及为什么行得通。”他说,直到最近我们才开始真正了解人工智能。
辛顿自己也说:“大多数会议只做一些微调,而不会努力思索讨论‘我们现在做的事情有什么不足?难点是什么?让我们专注这个问题。’”
外界很难理解这个观点,因为人们看到的是一个又一个伟大进步。但是人工智能最新进展的科学含量少于工程含量,甚至只是修修补补。虽然我们已经知道如何更好地提升深度学习系统,我们仍不了解这些系统的运作方式,也不知道它们是否有可能变得像人脑一般强大。
值得探讨的是,我们是否已经穷尽了反向传播的用途?如果是这样,说明人工智能已发展已经进入瓶颈。
AI的下一个革命,还要等待另一个30年?
如果你想目睹下一个划时代的发现,一个用更灵活的智能奠定机器基础的技术,你应该看看那些类似反向传播的研究(如果你在 80 年代了解到它):那些对尚未成功的理念坚持不懈的聪慧之人。
几个月前,我去脑、心智与机器研究中心(Center for Minds, Brains, and Machines,一家由多个机构成立的研究中心,总部位于麻省理工学院),参加我的朋友埃亚勒·德克特(Eyal Dechter)的认知学论文答辩。答辩开始前,他的妻子艾米、他家的狗鲁比(Ruby)和他们的女儿苏珊娜(Susannah)正围着他,给他打气。屏幕上有一张鲁比的照片,它旁边是婴儿时期的苏珊娜。当埃亚勒让苏珊娜指出照片上的自己时,她兴高采烈地朝自己婴儿时期的照片挥舞一条很长的可伸缩教鞭。走出房间的路上,她在妈妈身后推着一个玩具车,回头喊了一声“爸爸,祝你好运!”最后,她还用西班牙语说了一句“走啦(Vámanos)!”她才两岁。
“它现在还不算成功,但这只是暂时的。”
埃亚勒用一个有趣的问题开始了他的答辩:苏珊娜是如何通过两年的历练学会说话、玩耍和听故事的?人脑的什么特质使它如此善于学习?未来计算机能否这么迅速流畅地学习?”
我们基于已知的事物理解新现象,我们将一个事物分解成碎片,然后学习这些碎片。埃亚勒是一位数学家兼程序员。在他眼里,制作蛋奶酥这种任务相当于于极为复杂的计算机程序。但在学做蛋奶酥的时候,不需要学习无数类似程序中的微小指令,例如 “手肘旋转30度,低头看桌子,然后伸出食指,然后……”如果在做每个新任务的时候都要研究这样的细小指令,学习过程就会变得非常艰难,你也会在大量已经学到的知识中浪费时间。因此,我们只需要指出程序中高层次的步骤,比如“搅拌蛋清”,这样的高层次步骤本身已经覆盖了更小的子程序,比如“打破鸡蛋”和“取出蛋黄”。

计算机就做不到这点,这是它们看起来很笨的重要原因。要让一个深度学习系统学会识别热狗,你可能必须让它读取四千万张热狗图片。要让苏珊娜学会识别热狗,你只用给她一个热狗。过不了多久,她就能对语言产生更深的理解,不再只是知道某些词经常一起出现。与计算机不同的是,她脑海中有一个针对世界运作方式的模型。“让我感到不可思议的是,人们居然担心计算机会抢走他们的工作,”埃亚勒说,“计算机无法替代律师,不是因为律师能处理极其复杂的事情,而是因为他们能阅读和交谈。计算机和人类并没有靠近,两者之间的距离还很遥远。”
就算你微调一下问题,真正的智能也不会失灵。埃亚勒的论文重点阐述了计算机如何实现真正智能的理论,具体而言,就是计算机如何流畅地将已知信息应用到新任务上,并迅速从一个新领域的小白成长为专家。
他将这个程序称为“探索-压缩”算法(exploration-compression algorithm)。它让计算机像程序员一样工作,在创建更复杂程序的过程中建立一个可重复使用的模块化组件库。在对新领域一无所知的情况下,计算机搬弄、巩固所发现的内容,像人类小孩一样,在玩耍的过程中构建关于新领域的知识体系。
他的顾问约书亚·特南鲍姆(Joshua Tenenbaum)是人工智能领域论文被引次数最多的研究人员之一。我和其他科学家谈话时多半会提及特南鲍姆。2016年,AlphaGo在一场复杂的围棋比赛中打败了世界冠军,震惊了计算机科学家们。它背后的DeepMind团队中的重要成员曾是特南鲍姆的博士后。特南鲍姆参与了一家创业公司的工作,这家公司致力于让自动驾驶汽车直观地了解一些基础物理学,对其他驾驶员的意图也能做出一定的直觉判断,从而更好地应对从未遇到过的情况,比如一辆卡车冲到前面或他人强行超车。
埃亚勒的论文尚未转化为这种实际应用,更没有创造出任何胜过人类的程序。“埃亚勒研究的课题真的是特别,特别难,”特南鲍姆说,“这需要几代人才能解决。”
特南鲍姆留着灰白的长卷发。我们喝咖啡时,他穿着一件纽扣衬衫和黑色休闲裤。他告诉我,他想从反向传播的应用过程中寻找灵感。几十年来,反向传播一直是酷炫的数学理论,但没有真正解决任何问题。随着计算机的运算速度越来越快,工程设计越来越复杂,它突然发挥作用了。他希望同样的事情能发生在自己和学生的研究课题上,“但可能还要花几十年的时间。”
至于辛顿,他相信克服人工智能局限性的关键在于搭建“一个连接计算机科学和生物学的桥梁”。从这个角度看,反向传播是受生物学启发的计算机学突破;该理念最初并非来自工程学,而是来自心理学。因此,辛顿正尝试效仿这个模式。
今天的神经网络由大平面层组成,但人类新皮层的真实神经元不仅是水平分布成层的,还有垂直排列的。辛顿认为,他知道这些垂直结构的作用,比如在人类视觉系统中,这些结构确保我们在视角变化时保持识别物体的能力。因此,他正在搭建一个叫做“胶囊”(capsules)的人工视觉体系来验证这个理论。目前,他还没有成功;这些胶囊并没有显著提升神经网络的表现。但是,他研究反向传播时也遇到了同样的情况,而且持续了近 30 年。
“胶囊理论一定是对的,”他笑着说,“不成功只是暂时的。”
-End-









论坛新帖
频道总排行
医学推广
频道本月排行
热门购物
评论排行
- 2011年临床执业医师考试实践技能真...(13)
- 腋臭手术视频(11)
- 2008年考研英语真题及参考答案(5)
- 节食挑食最伤女人的免疫系统(5)
- 核辐射的定义和单位(5)
- CKD患者Tm与IMT相关(5)
- 齐鲁医院普外科开展“喉返神经监护...(5)
- windows7激活工具WIN7 Activation v1.7(5)
- 正常微循环(5)
- 美大学性教育课来真的 男女上阵亲...(4)